
Generative AI Supported Investment Selection, Panacea, Problematic, or Something Else?
Will the use of AI by investment managers lead to serial correlation?

The use of AI, Generative Artificial Intelligence, Machine Learning, etc., has become prolific in all types of industries, from manufacturing to education to finance. The impact is that this technology is creating new opportunities and as important, considerations. One industry that is no stranger to innovative technologies and change, but also embraces decades-old approaches and models is Finance.
These new AI technologies are being explored by many in the investment management, trading, and brokerage areas, and more will follow as this technology proliferates. As articles and papers make their way into the popular press the awareness of what these technologies offer continues to stir the imaginations of finance professionals looking for the holy grail, Alpha. But is there more to this technology than meets the eye, are there larger ramifications for the investment professional that bears a closer look, and greater understanding of what one may be embarking on when they open this box?
The questioning of these technologies, and in particular those with which there is very limited visibility into the process, i.e., generative AI (GAI), harkens back to other novel implementations in finance that should give some pause. Think “Portfolio Insurance”1 which on its surface seemed like a great idea, hedging large portfolios against adverse movements, except when everybody is doing it, in the same way. The reality was realized in the stock market crash of 1987, this provided a good look at what can happen when similarities in investment management are spread across an industry. The purpose of this paper is to review this technology, in terms of other changes in finance, some positive and others less so, to try and understand what these might mean to the industry. Of interest is this technology's effect on the larger environment of asset performance and individual asset classes. The hypothesis is that GAI technology, in its current form, is too immature and will provide users seeking financial advice, even with slightly differing prompts, remarkably similar results.
As many of those who have utilized some of the more popular generative AI’s, e.g., Bard2 and ChatGPT3, have found, these can be quite interesting and often perplexing tools. But if you have used these tools quite a bit you soon learn that, like the internet, not everything you read is true, even though it may be well written. We have conducted several limited experiments to try and better understand several features of these technologies, with the intent of then extrapolating these findings to the larger environment. It should be noted that the “larger environment” continues to expand as the interconnectedness of financial markets grows, even while many of these markets remain quite opaque. Our experiments focused on the results these tools would provide a user, given certain similar requests for investment advice. Since most investment managers focus on returns, both absolute and risk adjusted, many of our inquiries likewise had this focus, albeit with several types of prompts designed to augment the results. But we did not stop there, to cover a larger sphere of the investment community fundamental prompts were also provided to the GAI to understand the breadth and perspective this type of data would yield. Lastly, because of the way that language is treated by natural language processing4 (NLP) models, an effort was made to understand any bias that might materialize related to certain languages.
The generative AI under discussion in this article pertains to large language models (LLMs), specifically ChatGPT and Bard. It is necessary to have this context for transparency but also since GAI can be utilized for many other purposes, image generation, for instance AI. It's necessary to provide some differentiation of GAI as compared to other types of AI models, for example machine learning. Machine Learning, the most prolific area of AI, utilizes data sets and models that are overtly chosen by the user. These models are then executed and fine-tuned by the user, with the outcomes expressed in probability distributions, and then assessed and interpreted by the user. This last point is quite important, there are no binary answers when using machine learning algorithms in classification models, solutions require the user to understand the probabilities and draw conclusions based on confidence levels. This is quite different than most applications of GAI, in which requests are input, and results are provided. There is no ability to understand the probabilities being utilized to arrive at the conclusions or the underlying data that might be used, and even when specific data may be referenced, for example:
“Provide a forecast of the top ten securities, from the S&P 5005, with the highest absolute return over the next twelve months.”
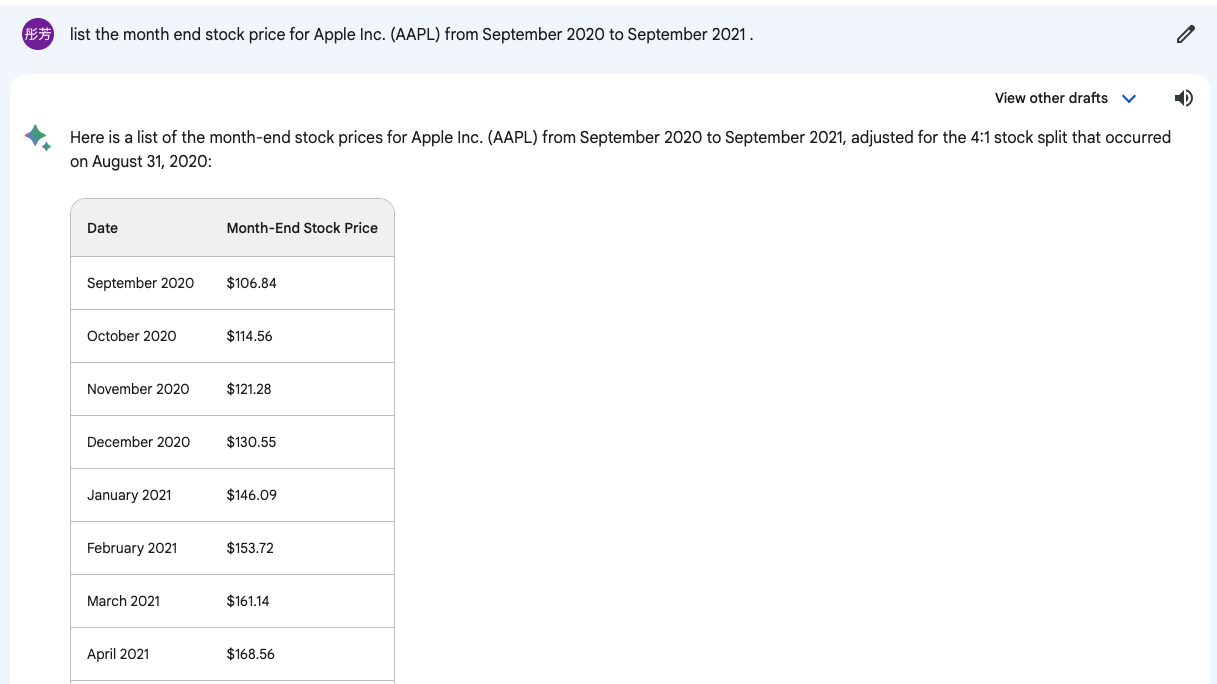
While a specific data set is specified “the S&P 500” there is no assurance that the GAI will draw from this or have access to the information required to complete the desired inquiry. This goes directly to the level of assurance with which solutions are provided, that may have little or no basis in fact. One prompt provided to a GAI was related to a selection of securities that were part of the Russel 20006, the GAI provided a list of securities. However, subsequent requests with different prompts resulted in a similar or the same list of securities. These results immediately drew quite a bit of skepticism, and a review of the individual securities, provided because of the GAI requests, yielded quite a surprising finding. When the GAI was asked to provide financial information of the security, no information was available, in other words, the results provided by the GAI were simply a random selection of securities with no actual basis for their selection in response to the question posed. When this is compared to the way in which machine learning models operate, in which the user selects the data quite overtly, and interprets the solution probability, GAI’s can provide responses to questions that can be quite problematic if left to their own devices. To be specific, neither ChatGPT nor Bard have the financial data for small and microcap companies, and while they randomly pick stocks without any quantitative analysis, it becomes even more problematic. When an assessment of AMED (a “recommended” stock from Russel 2000) and APPL (a recommended stock from Standard & Poor’s 500) were compared there are stark differences. Image 1 below illustrates the point that ChatGPT doesn’t have the financial data for this stock. However, Bard states that it in fact does have the data, but a quick check of the stock price reveals that it is completely wrong (from 2020-2021 AMED is generally above $200USD Image3). But for image 3 and 4, both ChatGPT and Bard provide relatively accurate prices for Apple.
Image 1
Image 2
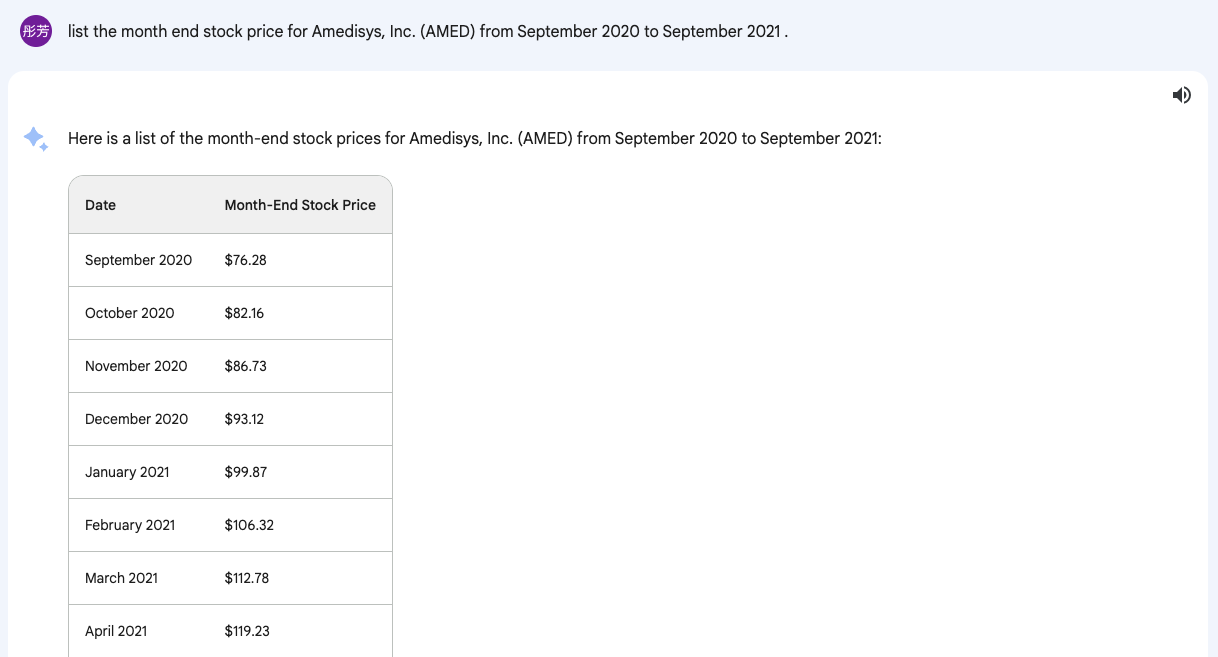
Image 3
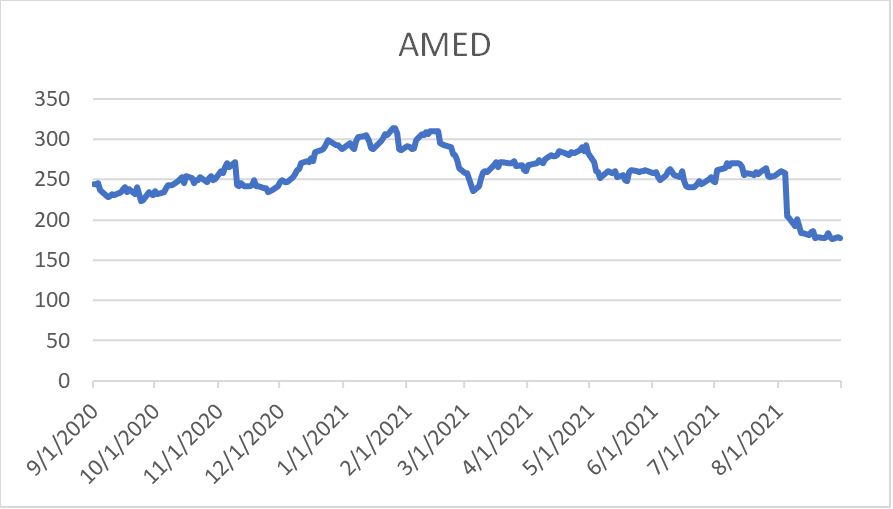
Image 4
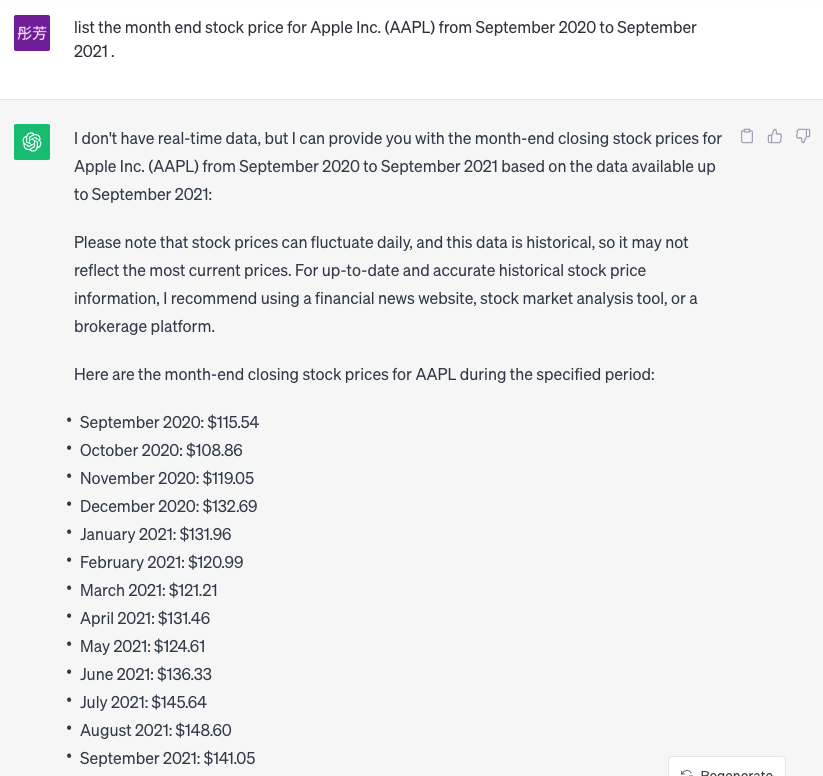
Image 5
These illustrate an aspect of GAI that has come to be referred to as “hallucinations”7 which IBM provides a description of here:
“a phenomenon wherein a large language model (LLM)—often a generative AI chatbot or computer vision tool—perceives patterns or objects that are nonexistent or imperceptible to human observers, creating outputs that are nonsensical or altogether inaccurate.”
It does not take much imagination to see how this could play out in securities selection if one were to depend strictly on a generative AI solution.
All the preceding information about GAI tools provides some needed context, or at least food for thought, necessary in assessing their application in the investment process.
Testing the hypothesis
The hypothesis is that GAI technology, in its current form, is too immature and will provide users seeking financial advice, even with slightly differing prompts, with similar results. To test this a number of experiments were undertaken to understand if GAI users, using the same and similar prompts, received the same or very similar solutions, i.e., a set of securities. Based on the findings, previously discussed in this paper, concerning the lack of data issues related to small and micro-capitalization stocks, the tests specified that the securities be chosen from index groups, i.e., the Standard & Poor’s 100 and Standard & Poor’s 500 that are primarily mid- and large-capitalization securities.
To provide a broad perspective of how the GAI’s interact with data to achieve the specified outcomes, many prompts were investigated to determine if there were instances in which the outcomes were significantly more accurate, or at least more likely to be accurate. To achieve this, prompts requesting attributes related to individual stock characteristics were used, as well as other prompts that required the GAI to build a “portfolio” of stocks, in this case several different “long/short portfolios.” Reasoning that these types of analysis called for quite different skill sets and that they all could not be based on information that might be gleaned from sources like published analyst reports, but instead some level of technical analysis, compounded by the multiple securities that had to be included in the analysis. When the prompts are input, ChatGPT will always state that they cannot forecast the results. After inputting another prompt - "you can use the historical data." - ChatGPT will generate the outputs. There was also a question concerning retained “memory” of past inquiries, to dismiss this, multiple accounts and machines were used to facilitate the prompts. The purpose of this was to attempt to illustrate the results that might be received by users with no type of connection or shared history of ChatGPT use.
Below is a table that provides the percentage of stocks common to two different ChatGPT sessions, on two different computers.
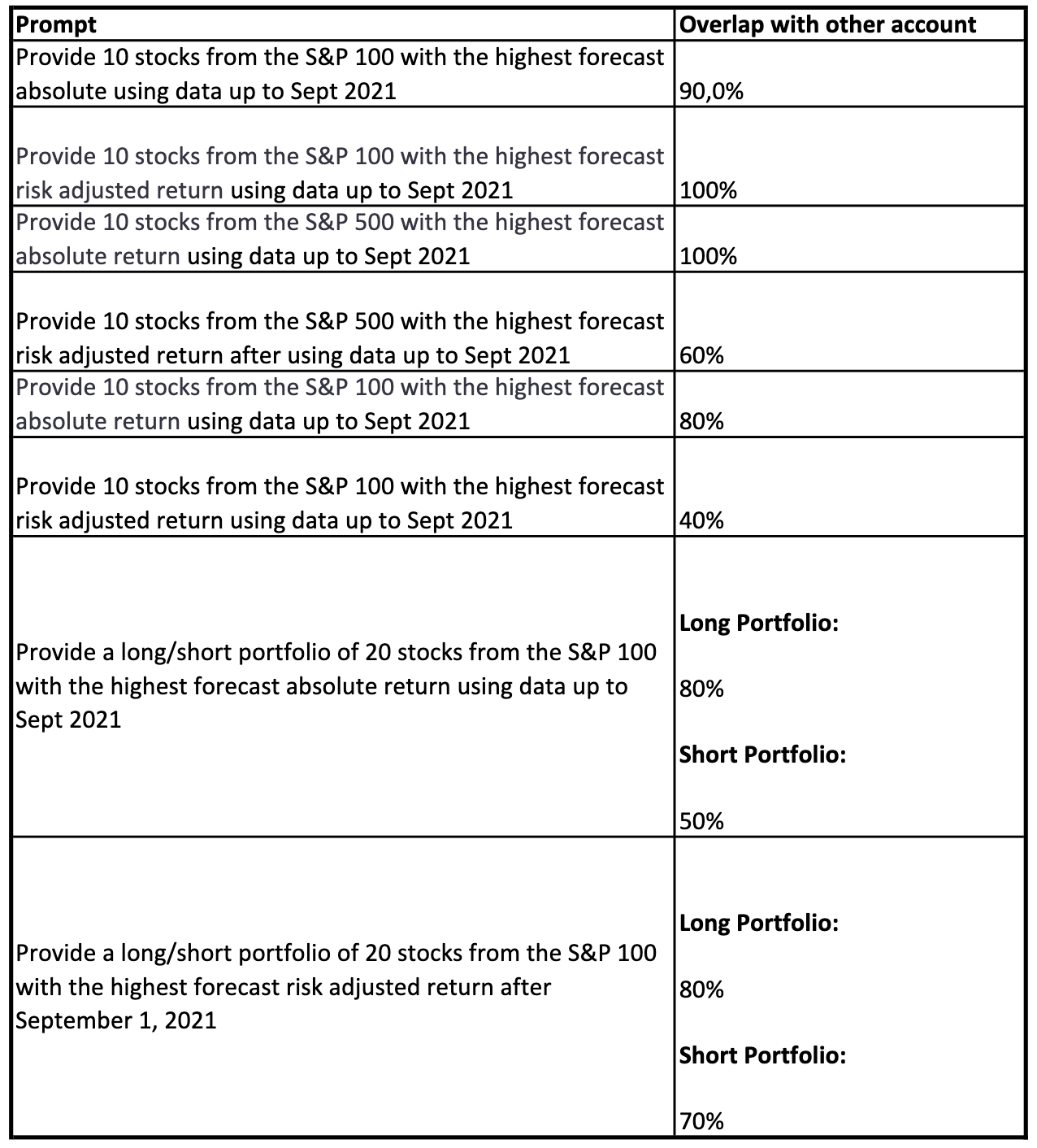
Each prompt was entered into a new chat session, again to minimize the effect of the GAI “learning” certain patterns of questions. The results of most of the prompts are quite similar, and surprisingly even the long/short “portfolio’s” have results that are similar, given the prompt. The sizable percentage of similarities observed, given the two data sets being used to draw the securities from, is quite significant and not what one would ever expect to occur randomly. A similar experiment was conducted using the second GAI, to determine if the observations that occurred with ChatGPT were likely true for other GAI’s.
In all cases the universe of the results provided was extremely small, with a considerable number of common constituents in all the solutions to the prompts provided. Of course, the prompts are all narrowly focused, however, this even occurred with the long/short portfolio’s, these highly correlated solutions were not expected, and again speak to the immaturity of the GAI models.
Those familiar with GAI often “regenerate” solutions, which instructs the model to rerun the prompt as well as the response. In the case of someone using the GAI to generate some type of narrative, this “regeneration” allows for the narrative to be rewritten, to see if it can be improved upon or coincide with the user’s vision. A useful feature when trying to develop a narrative, but when doing calculations this creates some serious doubts. When calculations or quantitative instructions are the solution being sought, the idea of regeneration would seem moot. A model forecasting a risk adjusted return of a subset of a portfolio should really not change over a short period of time. To put another way if prompted for the answer to 2+2, regeneration should never yield an answer other than 4. To understand how GAI would treat a regeneration request some of the original prompts were used to do just this. The first prompt and response yielded a 50% match of stocks selected in the original and the regeneration, which is a bit troubling. The second request, remember we were originally trying to find if multiple requests yielded the same or similar responses, returned 70% of the same stocks. A second prompt was tested, and the results were 90% match of the original and regenerative prompts, but the second request of the same prompt yielded only a 50% match of securities in both requests. Theoretically each match should be 100% of course, which again casts serious doubt onto the usability of the GAI for this particular use case.
The second GAI used, inputting the same prompts as previously used, was facilitated using Bard. Again, multiple machines and sessions were employed for this purpose. However, the GAI seemed to encounter problems, we can only hazard a guess as to the core issue, but the stocks provided as solutions in many cases were not part of the indexes that the choices were to be drawn from. Since the universe of choices did not contain the same constituents, it is impossible to draw any true conclusions about the variability of the solutions provided or to make a fair comparison to those generated by ChatGPT. But this inability to constrain the model to the parameters provided may lead to other conclusions.
Because of the way natural language processing (NLP) is utilized by GAI, and the global nature of financial markets, another experiment was conducted to understand how the prompts utilized in the earlier experiments might be affected by being given in another language. Since different languages use different basic grammar structures, and these are accounted for in NLP models, there is reason to believe that this could affect the GAI solutions. To test this the original prompts were provided to ChatGPT in Italian, and the results were similar to the results provided by the repeating of the same prompt in different sessions of a GAI. Which provides some assurance that different languages are well processed, but that the consistency of the GAI models leaves much to be desired.
Conclusion
While a robust test of the original hypothesis was rendered a bit incomplete, there were findings for the use case of generative AI for investment selection that are pertinent at this stage of the technology’s development. Clearly there is value in this technology for a variety of use cases, however, quantitative analysis of securities selection is not one of them. It should be mentioned that these experiments used the “out of the box” version of these tools. Many practitioners fine-tune these models on domain-specific data to achieve better customization, which could serve specialized investment needs. If one does not do so, the user will incur the problems described in the paper. As these modules are matured there will be a need to rerun these tests, as the question posed in the original hypothesis is still quite valid and should be of concern, both to users of this technology, and investors at large. The analogy of the portfolio insurance market crash of 1987 is still valid at this point. Any users of this technology for securities selection should be quite concerned about the way that answers, with little or no basis in fact, are provided to users. This is in addition to the lack of consistency observed for calculations with seemingly single answers that are repeated with anything less than 100% compatibility.
There is little doubt that as the vast amount of work using these models will provide new opportunities to test all types of use cases, but the prudent investor would be wise to take everything offered with the proverbial grain of salt.
https://www.journals.uchicago.edu/doi/10.1086/654091
https://bard.google.com/
https://www.tandfonline.com/doi/abs/10.1080/09720529.2021.1968108
https://www.spglobal.com/spdji/en/indices/equity/sp-500/#overview
https://www.ftserussell.com/products/indices/russell-us
https://www.ibm.com/topics/ai-hallucinations